Hans-Peter Schramm hat geschrieben:... als ich in ganz anderem Zusammenhang mit Abbildungen bzw. Transformationen zu tun hatte,
Michael_Poschmann hat geschrieben:... inwieweit IVLZ-Unterlagen von dieser Technologie profitieren können.
Affine Abblidungen/Transformationen sind so exotisch nicht. In ihrer einfachen Form, nur Translation und Rotation, sind sie Basis jeder 3D-Szene, so auch in Zusi, mit dem vermutlich einzigen Unterschied, dass man sie dort nicht wahrnimmt.
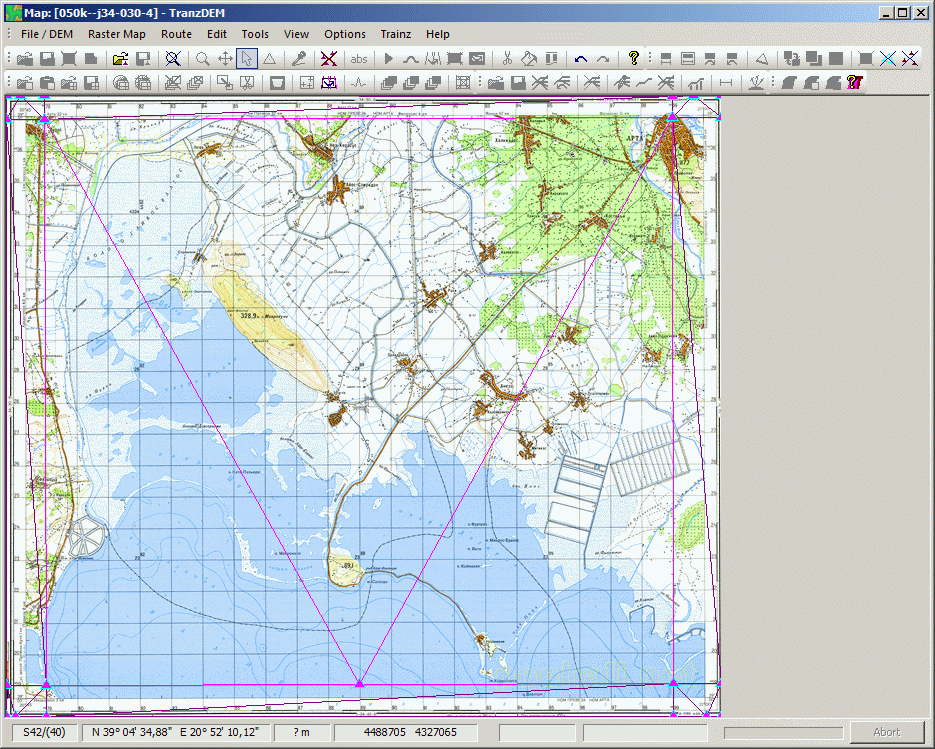
Ob sich der Ansatz unregelmäßiger Dreiecksnetze für verzerrte Gleispläne wirklich praktikabel nutzen lässt, kann ich noch nicht sagen und will hier auch nichts versprechen. Der Algorithmus selbst funktioniert, und wird für Karten und Pläne wie im gezeigten Beispiel schon deutliche Verbesserungen bringen. Die Gleispläne bergen eine zusätzliche Herausforderung: Die Aufstellung des Dreiecksnetzes selbst. Wie es formal aussehen sollte, ist einfach vorzustellen. Aber es dann auch zu bemaßen steht auf einem anderen Blatt. Ich werde noch ein wenig experimentieren.
Zurück zu C++.
Diesen Beitrag möchte ich einer Softwaretechnik widmen, die sich
RAII abkürzt, Resource Acquisition is Initialization, leider völlig unpassend, um aus dem Namen den Nutzen abzuleiten.
Als sich das OO-Paradigma vor etwa 15 Jahren weitgehend etabliert hatte, und die informationstechnischen Vordenker mit ihren Thesen den Weg zu aufgeschlossenen Entwicklern fanden - eine mittlere Sensation, waren doch vorher Informatik und Programmierung zwei verschiedene Welten - verbreiteten sich auch kleinere Techniken und Verfahren, die zu besserem Softwaredesign führten. Ein Stichwort sind Entwurfsmuster, Design Patterns, Klassenstrukturen, die bestimmte Teilaufgaben auf immer die gleiche Art lösen, ohne unbedingt als Klassenbibliothek ausgeprägt sein zu müssen. Das Singleton- oder Factory-Pattern beispielsweise wird jeder kennen, der in der OO-Welt zu Hause ist. Warum RAII nie den Titel Pattern bekommen hat, entzieht sich meiner Kenntnis, es ist auch nicht komplexer als Singleton.
Die Idee von RAII ist simpel. Jede Ressource, die in einem Programm benötigt wird, zum Beispiel der Zugriff auf eine Datei, muss auch wieder freigegeben werden. Bei RAII definiert man die Freigabe bereits in dem Moment, in dem man die Ressource akquiriert, mit Hilfe eines Verwaltungsobjektes. Wird das Verwaltungsobjekt angelegt, wird die Ressource akquiriert, wird das Verwaltungsobjekt zerstört, wird die Ressource freigegeben.
Das Prinzip dabei ist Konstruktor und Destruktor. OO-Sprachen, in denen die Klassen dedizierte Destruktoren haben, wie C++, tun sich besonders leicht. Die Verwaltungsobjekte werden als lokale Variablen einer Klassenmethode auf dem Stack angelegt. Wird die Methode verlassen, völlig unabhängig davon wann und wie, wird der Stack bekanntlich aufgeräumt und das Verwaltungsobjekt dabei zerstört. Hierbei wird dessen Destruktor aufgerufen, und der gibt die Ressource, immer, in allen denkbaren Fällen einschließlich Exception, absolut zuverlässig.
OO-Anfänger tun sich manchmal schwer, wenn sie den Sinn und die Möglichkeiten von Konstruktoren und Destruktoren erfassen sollen. RAII ist ein hervorragendes Beispiel für Klassen, die überhaupt nur aus Konstruktor und Destruktor bestehen.
Garbage-Collection-Sprachen wie C# oder Java verfügen nicht über dedizierte Destruktoren. Hier muss man sich behelfen und RAII in einen try-finally-Block packen. Das ist natürlich fehlerträchtig. In C# stand von Anfang an das Schlüsselwort using zur Kapselung eines RAII try-finally zur Verfügung, für Java wurde es mit Version 7 im letzten Jahr endlich nachgeholt.
Die weiteren Betrachtungen bleiben bei C++ und sollen konkrete Beispiele vorstellen.
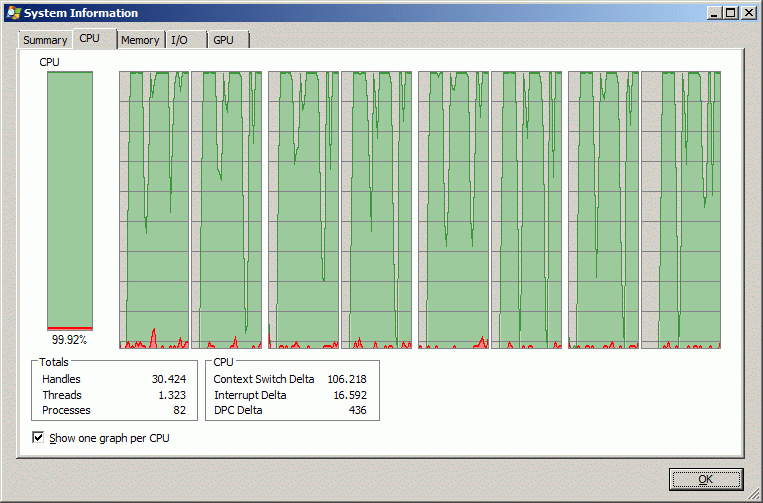
Die Beispiele stehen in direktem Zusammenhang mit meinem vorigen Beitrag. Die dort vorgestellten parallelen Schleifen können auf verschiedene Art verlassen werden. Im Optimalfall durch vollständige Abarbeitung der Schleifen und normale Rückkehr zu höherer Ebene. Ein zweite Möglichkeit ist der vorzeitige Abbruch durch den Benutzer. Threads werden immer von innen gestoppt. Der Abbruchswunsch muss dem Thread mitgeteilt werden. Das geschieht hier über ein einfache boolsche Variable, deren Zugriffsoperationen als atomar gelten, also nicht mehr Mutex udgl verriegelt werden müssen. Zum Beenden der vielen parallelen Threads reicht leider kein vorzeitiges return, denn dieses würde nur einen Thread terminieren. Vielmehr muss eine Exception geworfen werden, die von einer der Verwaltungsklassen der Parallelschleifen bibliotheksintern abgefangen wird, und sämtliche anderen Threads ebenfalls von innen beendet. Und wiederum Exceptions, diesmal unvorhergesehene, sind auch die dritte Möglichkeit des Abbruchs. TransDEM bewegt sich gerne immer wieder in der Nähe der allozierbaren Speicherobergrenzen, manche Benutzer sind da gnadenlos. Man muss also damit rechnen, dass es irgendwann nicht mehr reicht.
In allen Fällen von Schleifenende soll dafür gesorgt werden, dass unabhängig von der Art der Rückkehr, ob über normalen Ablauf, oder über Exception, alle lokalen Variablen oder temporär geänderte Zustände ordentlich wieder aufgeräumt werden, ein typisches Anwendungsfeld für RAII.
Das erste Codebeispiel bezieht sich auf die Klasse, die mir bei der Parallelisierung (letzter Beitrag) zunächst Ärger gemacht hatte, weil sie die klassische CriticalSection benutzt hatte, hier aber dringend ein Spinlock angeraten war.
Ich habe daher zunächst jene Klasse namens GridConversion um den Spinlock intern erweitert, und eine Funktion eingefügt, mit der man hin und her schalten kann. Wichtig ist jetzt, und damit kommt RAII ins Spiel, dass einmal auf Spinlock umgeschaltet, nach Verlassen der Parallelschleife auch sicher wieder zurückgeschaltet wird. Dazu dient die folgende RAII-Klasse, die ich üblicherweise mit Postfix "Guard" versehe.
Code: Alles auswählen
class GridConversionSpinlockEnableGuard {
public:
// ctor
GridConversionSpinlockEnableGuard (GridConversion & gridconv) :
m_gridconv (gridconv)
{
m_gridconv.useSpinlock (true);
}
// dtor
~GridConversionSpinlockEnableGuard (){
m_gridconv.useSpinlock (false);
}
private:
GridConversion & m_gridconv;
};
Die RAII-Klasse hat, wie vorher eingeführt, nur Konstruktor und Destruktor. Die Konstruktor wird das Objekt von GridConversion mitgegeben, auf welches sich die Umschaltung bezieht. Der Konstruktor schaltet im referenzierten Objekt die Spinlock-Nutzung ein, der Destruktor wieder aus.
Angewandt wird das per Einzeiler:
Code: Alles auswählen
void myFunction () {
// ...
// here comes the RAII object
GridConversionSpinlockEnableGuard grdConvSpinlockGuard (m_gridConv);
// parallel loop where spinlock is required
parallel_for (0, max, [&](unsigned loopIdx) {
// ...
// Lambda expression with all the code of the parallel loop
// using m_gridConv functions, now secured by spinlock
// ...
});
}
Wird myFunction () verlassen, auf welche Art auch immer, so wird das Guard-Objekt zerstört und m_gridConv schaltet zurück auf CriticalSection.
Zweites Beispiel. Hier wird eine RAII-Klasse aus der Microsoft-Parallel-Bibliothek benutzt "Concurrency::scoped_lock", um einen Zugriff per Spinlock "Concurrency::critical_section" zu verriegeln.
Man beachte die Namensgebung dieser Microsoft-Klassen, Kleinschreibung und mit Unterstrich, sehr untypisch für MS aber sich nahtlos integrierend in die C++-Standardbibliothek.
Code: Alles auswählen
void someFunction () {
// ...
// a critical section as a spinlock object
Concurrency::critical_section mtx;
// parallel loop where spinlock is required
parallel_for (0, max, [&](unsigned loopIdx) {
// ...
// Lambda expression with all the code of the parallel loop
// ...
// a spinlock guard
Concurrency::critical_section::scoped_lock gd (mtx);
triWghtArr[m].push_back (make_pair (pTri, wght));
});
Der zu sichernde Zugriff auf triWghtArr erfolgt ganz zum Schluss des Lambda-Ausdrucks, somit wird unmittelbar der Zuweisung das Guard-Objekt wieder zerstört und der Spinlock freigegeben.
Ein RAII-Variante für Pointer, Heap statt Stack, folgt im nächsten Teil.